
ChatGPTの登場で一気に知名度が上がった生成AIですが、同時に話題となったのはAIの回答が正確ではない場合がある、ということでした。また、困ったことにこの誤回答は間違っているだけでなく、AIはあたかも正しいことのように答えてしまうのです。いわば生成AIのつく「ウソ」。生成AIの回答が正しいかどうかは人間には判別困難なことも多く、これはAIの信頼性に大きく影響します。このようなAIのウソをハルシネーションといいますが、対策はあるのでしょうか? 本コラムでは、AIのハルシネーション対策として注目を集めているRAGについて解説していきます。
RAGとは
RAG(ラグ)とは、Retrieval-Augmented Generationの略で、検索拡張(増強)生成と訳されます。これは検索機能を使って生成を拡張するという意味合いで、LLM(大規模言語モデル)による生成に独自の外部情報を組み合わせることで、生成AIの回答精度を向上させる技術のことです。
たとえば近年話題になっているChatGPTでいえば、その情報源は基本的にインターネット上に公開されている情報であり、これを基に学習し回答を生成しています。つまり、私企業の社内規定や業務マニュアル、クローズされている情報にはアクセスできないので、虚偽の回答が生まれることがあるのです。
RAGが注目されている背景

近年はChatGPTをはじめとする大規模言語モデルを業務に活用し、社内業務の効率化を進める企業が増えています。たとえばパナソニックでは、AIのアシスタントを業務に導入し、社内で1日5,000回も使われるようになっています。生成AIは製品開発にも利用されており、自社製品のモーター設計にAIを用いて人間が設計したモーターと比べて15%も出力が高いモーターの開発に成功しています。また、旭鉄鋼では業務の改善活動に生成AIを導入し、社内にあった改善活動の過去事例から目的や状況に合った情報を引き出して新しい改善活動に活かすようになっています。このように、普段の業務活動だけでなく社内情報の利用や設計業務にまで生成AIは活用されるようになっているのです。
ただし一般的な大規模言語モデルには大きな弱点があります。それは主に以下のようなものです。
企業独自の情報が扱えない
ChatGPTをはじめとする一般的な大規模言語モデルは、その情報源が先述のようにインターネットになっています。したがって、クローズな環境に置かれている企業独自の情報は、扱うことができません。
最新情報が反映されない
インターネット上にある情報は、常に最新のものとはかぎりません。むしろ更新されない情報が最新情報と入り交じって存在しており、非常に混沌とした状況になっています。インターネットで情報を得る一般的な大規模言語モデルの回答には、最新情報が反映されない可能性があるのです。
ハルシネーションが発生する
上記のような間違った情報や古い情報から生成AIが答えを導くと、結果としてハルシネーションが発生することになります。
上記で紹介した生成AIの成功事例には、これらの問題を解決する手法が用いられています。その有効な手段の1つがRAGであり、これがRAGが注目されている背景なのです。
ハルシネーションとは
RAGの仕組みやメリットを説明する前に、もう少しハルシネーションについて説明しておきましょう。

ハルシネーションはなぜ起こるのか?
ハルシネーション(hallucination:妄想、幻覚)とは、AIが事実に基づかない情報を生成する現象のことで、まるで幻覚でも見ているかのように事実とは異なる内容を、もっともらしく回答してしまうことをいいます。このようなハルシネーションが起こってしまう要因は主に2つあり、「学習データの品質が悪い(正確ではない)場合」や「学習モデルの構造(アーキテクチャ)や学習プロセスに問題がある場合」といわれています。
たとえば、無料版のChatGPTではしばしば事実と異なる回答がなされ、一時期はその誤答が面白おかしくSNSやニュースで取り上げられました。無料版のChatGPTでこのようなハルシネーションが起きやすいのは、正しい情報と誤った情報が混濁しているWebサイトからの情報を回答に用いているからです。つまりこれは、学習データの品質が悪い場合に相当します。無料版のChatGPTだけでなく、他の大規模言語モデルでも学習するプロセスが間違っていたり、誤った情報が与えられたりすればハルシネーションは起きてしまいます。
ハルシネーションの対策は3つ
上記のような、大規模言語モデルのハルシネーションを防ぐ方法は3つあります。
学習データの品質向上
ハルシネーション防止と大規模言語モデル活用の一番の対策は、学習データの品質向上です。誤回答につながる間違った情報や古い情報を廃し、また勘違いしやすい表現や情報の構造を改善してAIに正しい情報を認識させる工夫をするのです。
出力結果にフィルターをかける
大規模言語モデルが回答しようとする結果に、誤った情報や偏見を含む情報がないように制限をかける方法です。ただし、誤った情報や偏見の定義は難しく、生成された結果からこれらを判定することも困難な場合があります。
RLHFによる調整
RLHFとはReinforcement Learning from Human Feedbackの略で、人間からのフィードバックにより強化学習を実施するという意味になります。大規模言語モデルが生成した回答に人間がフィードバックを行い、ファインチューニング(微調整)を行う手法です。RLHFはChatGPTや他の大規模言語モデルでも用いられているAIのトレーニング方法で、人間の価値基準が反映されやすくなるため安全で無害な回答に寄与するといわれています。
RAGの仕組み
RAGはファインチューニングや構造化、エンベディングと混同されることもあります。まずRAGの仕組みを確認し、RAGと他のハルシネーション対策が根本的に違っていることを確認しておきましょう。
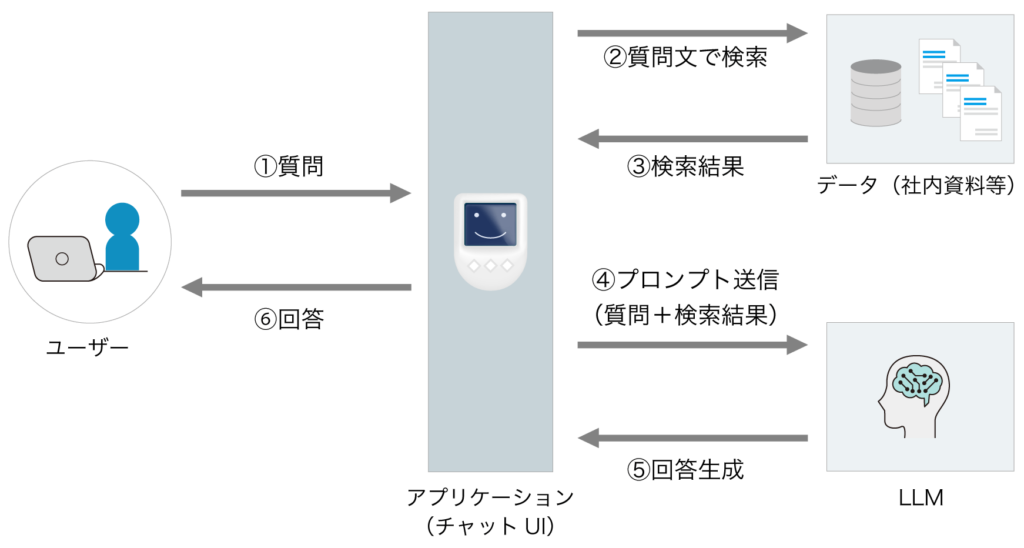
RAGはAIに扱わせたい情報を独自に用意し、この情報を検索させることで虚偽の回答が生まれることを防ぐ仕組みです。一般的には独自の情報を格納した外部データベースを用意し、質問が入力されるとはじめにこの外部データベースを検索して最適な情報を抽出します。次に抽出した情報と入力された質問をプロンプトに含めて大規模言語モデルに送ります。そしてそれらの受け取った情報に基づき大規模言語モデルが回答を生成するというわけです。このような仕組みにすることで、大規模言語モデルが生成に利用する情報をコントロールし、誤情報を検索・生成することを防ぐ手段となります。また、このようなデータベースに社内規定や業務マニュアル、さまざまな社内情報を格納しておけば、社員が社内情報を検索するツールとしても活用できます。
RAG以外のハルシネーション対策
ファインチューニング
ファインチューニングとは、いったん学習を終えた大規模言語モデルを別のデータで再学習させ、微調整(Fine-tuning)を行うことをいいます。大規模言語モデルを特定の目的に合わせてカスタマイズすることで、誤回答を生成しにくくする手法です。
構造化
構造化とは、学習データを大規模言語モデルが理解しやすいように明確なフィールドやカラムに分割・整理することをいいます。つまり、蓄積されたデータをAIが誤解なく理解するように、関係性を明らかにして構造化するのです。
エンベディング
エンベディングは、大規模言語モデルがより効果的にデータを処理し、理解しやすい状態にデータを最適化(ベクトル化)することです。データのパターンや関連性を分析し、高次元データをより扱いやすい形式に変換する技術です。
RAGは上記のような手法とは違い、質問応答や知識生成のタスクにおいて検索機能とテキスト生成機能を組み合わせ、従来の大規模言語モデルを超える正確さと詳細な情報提供を実現するものです。
RAGの活用で期待できるメリット
RAGを活用することで、以下のようなメリットが期待できます。
企業固有情報の対応
大規模言語モデルによる生成に独自の外部情報を組み合わせることにより、公開されていない情報や企業固有の情報も扱えるようになります。社内規定や顧客情報といった企業固有の情報を使い、社内問い合わせや顧客分析などにも生成AIを活用可能です。
最新情報の提供
たとえば無料版のChatGPTでは2022年1月までのデータしか扱えませんが、大規模言語モデルに最新の情報を与えることにより、最新の情報を加味した回答を生成できるようになります。
詳細で正確性の高い回答
インターネットには正しい情報と間違った情報が混在していますが、RAGを活用することでAIからの詳細かつ正確性の高い回答を期待できるようになります。
RAGの活用のメリットは、ハルシネーションのリスクを減らし、大規模言語モデルが幅広く正確な情報を扱えるようになることです。
RAGの活用例

固有の情報や最新の情報が大規模言語モデルで扱えるというRAGの特徴を活かせば、以下のような活用方法が考えられ、またすでに活用も始まっています。
カスタマーサポート
自社の製品やサービスの情報をデータベースに登録しRAGで活用すれば、顧客からの問い合わせに対してチャットボットによる正確な回答が可能になります。また実際のオペレーターが電話やチャットで顧客対応する場合でも、生成AIを「回答情報を検索するツール」として活用することにより効率と正確性を向上させられます。
社内ヘルプデスクへの活用
社内規定や業務プロセスをデータベースに登録すれば、今まで社内のヘルプデスクやバックオフィスの担当者に来ていた問い合わせを減らすことが可能になります。また、これらの担当者が専門知識をもつ必要もなくなるので、属人化の解消や働き方改革にもつながります。
営業資料やコンテンツの作成
ChatGPTや他の大規模言語モデルなどを使っても営業資料やメール文を作ることはできますが、自社独自の情報を使った営業資料やコンテンツは生成できません。さまざまな営業資料をデータベースに登録しておけば、RAGを使って効率的に営業資料やその他の独自コンテンツを制作できます。また、営業情報の他に社内規定や業務プロセスをデータベースに登録しておけば、効率的なナレッジマネジメントを推進することも可能です。
まとめ
ChatGPTをはじめとする大規模言語モデルは非常に有用である一方、情報の鮮度や正確性に問題をもつ場合があります。これらを解決する手段であるRAGは、今後ハルシネーションの主流な対策となっていくことでしょう。大規模言語モデルを活用したAI製品をお選びの際は、RAGに対応した製品を検討するようにしましょう。
RAGを導入したいならイクシーズラボのCAIWA Service Viii
AIチャットボットの先駆者として豊富な実績と経験をもつ株式会社イクシーズラボは、運用が容易で高性能なCAIWA(カイワ)シリーズを展開しています。
イクシーズラボの提供するCAIWA Service Viiiは、RAG技術を活用した「ChatGPT連携機能」を備えていて、社内データを活用し構築運用の手間なく企業固有の問い合わせ対応を自動化できます。なお、このRAG機能には、ハルシネーションを回避する仕組みが整っているため安心して利用できるようになっています。
高度なAI技術が組み込まれたCAIWA Service Viiiを導入することで、ナレッジの有効活用と業務効率化を効果的に実現できます。
ハルシネーション対策が整ったRAG機能搭載!
AIチャットボットCAIWA Service Viii
Viiiは、導入実績が豊富で高性能なAIチャットボットです。学習済み言語モデル搭載で、ゼロからの学習が必要ないため、短期間で導入できます。導入会社様からは回答精度が高くメンテナンスがしやすいと高い評価をいただいています。
