
学習データの品質やAIモデルのアーキテクチャ、学習プロセスが要因となって発生してしまう生成AIのウソ「ハルシネーション」。AIによって生成された結果が間違っているのに、さも本当のことのように回答されてしまうため非常にやっかいな問題です。このハルシネーションを完全に防げるわけではありませんが、生成AIのウソを防ぐ有効な手段がRAGの導入です。今回はRAGを導入する前にチェックしておくべきポイントと導入時の注意点や必要となる開発について解説していきます。
RAGの概要
RAG(ラグ)とは、Retrieval-Augmented Generationの略で、検索拡張生成と訳されます。これは検索機能を使って生成を拡張するという意味合いで、LLM(大規模言語モデル)による生成に独自の外部情報を組み合わせることで、生成AIの回答精度を向上させる技術です。
近年話題となっているChatGPTや一般的に無料で使える生成AIは、インターネット上に公開されている情報を元に回答を生成しています。インターネット上にある情報は間違っているものや古いものも多く、これがハルシネーション(誤回答)の元凶となります。また、一般企業の社内規定や業務マニュアル、クローズされている情報にはアクセスできないため、企業固有の質問を受けた際に、インターネット上の情報を元に回答を生成するため、正確な対応はほぼ不可能です。
RAGはLLMが内部にもつ知識(ネット上に公開された情報が元)だけでなく外部の信頼できる情報源を利用することで、モデルが誤った情報を生成するリスクを低減し、より正確で信頼性の高い回答を提供する仕組みなのです。
検索フェーズと生成フェーズ
RAGはその名の通り、検索フェーズと生成フェーズに分けて回答を生成します。検索フェーズでは、ユーザーからの質問に関連するスニペット(断片)をアルゴリズムが検索し、正答に必要と思われる情報を取得します。次に、この情報がLLMに渡され適切な文章にまとめられて(生成されて)回答されるのです。これらはそれぞれ別のシステムとして動くため、シームレスに統合するためには検索技術と生成技術含め高度な専門技術が必要です。
RAGに必要な開発と実装ハードル
ハルシネーションを防止するための有効手段であるRAGは、多くの専門的な技術を組み合わせる必要があるため、開発におけるハードルが高いといえます。また、導入前にチェックしておくべきポイントや事前に準備しておくべき事項があります。参考までにそれらをご紹介します。

検索用データベース構築と前処理
まずRAGが外部情報を利用できるようにするため、インデックス化(検索用データベースの構築)を行います。しかし、PDFやExcelなどのドキュメントファイルはインデックス化の際に、適切ではない形式で取り込まれることもあります。例えばPDFはフッターやページ番号が本文の途中に挿入されてしまったり、Excelでは行と列がバラバラになったりして、情報として正しく検索されなくなってしまうのです。このような問題を防ぐには、前処理でデータをテキストパース(テキスト形式に変換)し、適切なチャンク(後述)を抽出する工夫が必要です。しかし、この処理は非常に高いハードルとなります。
高度な検索技術の実装
先述のように、RAGは検索フェーズと生成フェーズに分けて回答を生成します。回答に必要な情報抽出の精度を上げるには、高度な検索技術の実装が必須になります。
チャンク抽出の工夫
チャンク(chunk)とは、英語で主に「かたまり」という意味をもつ名詞で、生成AIに関わる意味としては、データや情報を扱いやすくするために分割した状態を表します。生成AIの回答の良し悪しは、最適なチャンクをきちんとピックアップできるかが重要になります。また、抽出したチャンクの渡し方にも工夫が必要で、どの程度の量のテキストを渡すかなど(上位10位以内など)、トライアンドエラーを繰り返し、最適な方法を見つけ出す必要があります。
エンべディング(Embedding)
エンべディングとは、自然言語の単語や文を数値ベクトルに変換(ベクトル空間に配置)し、コンピュータがその意味や関係性を効率的に理解・処理できるようにするプロセスです。
Embeddings APIやLangChainライブラリを使うことでテキストをベクトル化することが可能ですが、適切なモデルの選択と調整、料金や制限、そしてデータのセキュリティに注意する必要があります。ベクトル化したデータは専用のベクトルデータベースを用意する必要があり、そこに格納します。
検索については、Amazon Kendra、Azure AI Search、Elasticsearchなどの検索システムがよく利用されています。
適切なプロンプトの開発
プロンプト(prompt)とは、ユーザーが生成AIに入力する指示や質問のフォーマットを指します。上記のような工夫でいかに検索フェーズで適切な情報を抽出できても、生成フェーズにおいて適切なプロンプトで生成AIに命令しなければ的確な回答は生成できません。生成AIが正確な回答を生成できるようなプロンプトをあらかじめ開発(プロンプトエンジニアリング)する必要があります。
RAG開発の全体像
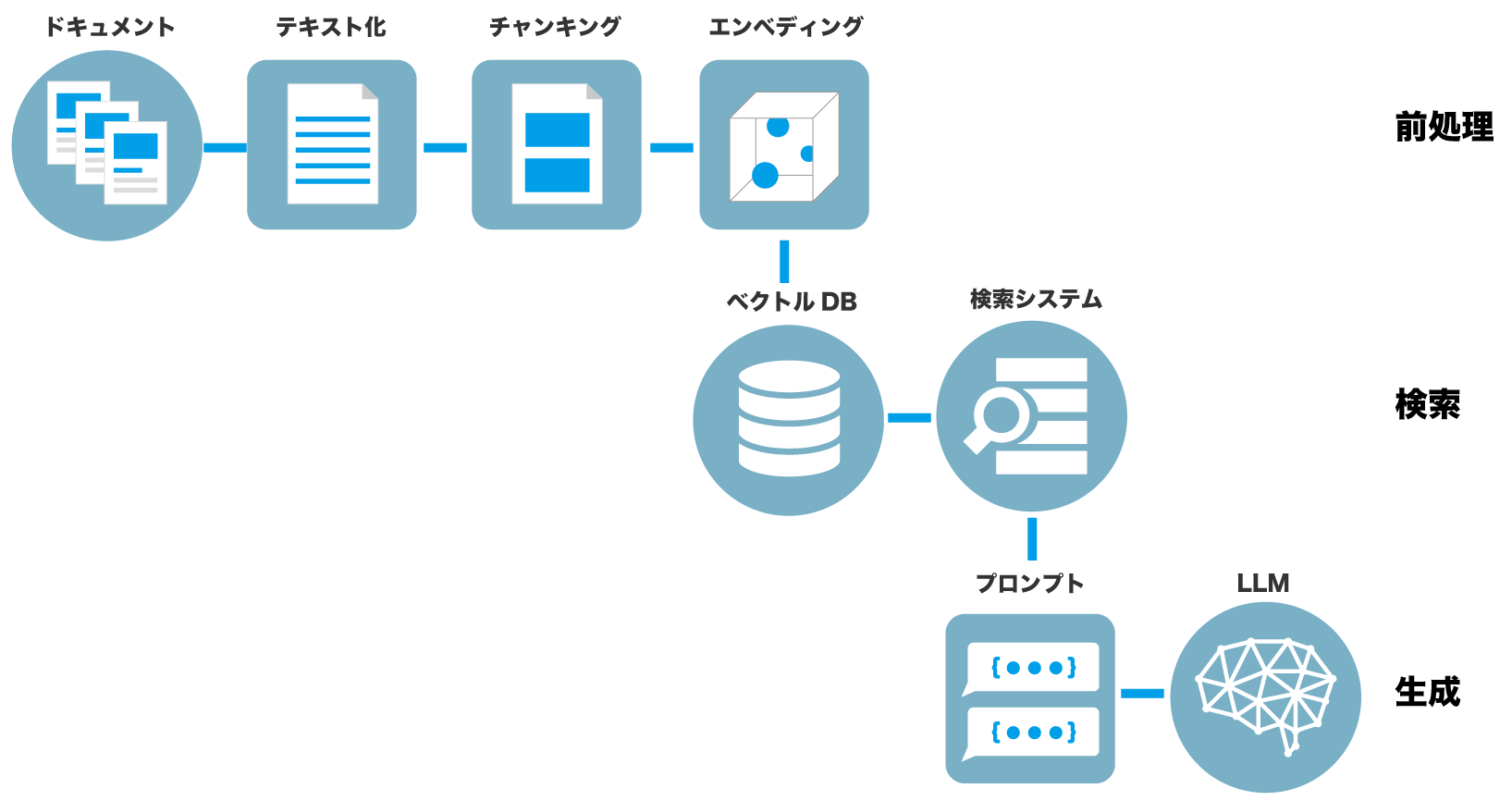
ハルシネーションへの対策
RAGで生成AIに外部情報を与えたとしても、ハルシネーションを完全になくすことはできません。RAGで解決できないハルシネーションについては、以下のような対応が必要になります。
学習データの品質向上
誤回答につながる間違った情報や古い情報を外部情報から削除し、勘違いしやすい表現や情報の構造を改善してAIに正しい情報を認識させる工夫をします。
出力結果の検証
生成AIが回答しようとする結果に、誤った情報や偏見を含む情報がないように制限をかける方法です。ただし誤回答や偏見の定義は困難で、効果には懐疑的な部分があります。
適切な情報が抽出できなかった場合の工夫
上記のような問題への対策として、検索段階で適切な情報が見つけられなかった場合に、曖昧もしくはいい加減な回答を生成させないような工夫をしておくことも1つの方法です。例えば、適切な情報が見つけられなかった場合、回答として「ドキュメントからは回答するための最適な情報が見つけられませんでした」と表示するようにしておくことなどです。
RLHF
RLHFとはReinforcement Learning from Human Feedbackの略で、人間からのフィードバックにより強化学習を実施するという意味になります。このハルシネーション対策は、LLMが生成した回答に人間がフィードバックを行い、ファインチューニング(微調整)を行う方法です。人間の価値基準が反映されやすくなるため、安全で無害な回答が期待できます。

応答時間の短縮対策
RAGは生成だけでなく、検索含め複雑な処理をいくつか組み合わせるため、回答までの時間(応答時間)が長くなります。そのため、応答時間を短くする工夫が必要です。
データの構造化と整理
データの構造化(事前に定めた構造にデータを整形すること)と古い情報、誤情報の整理を行うことで、AIの検索効率は上がり、生成時間を短縮できます。また、長い文章を整理し、チャンク分割を実行(チャンキング)することも有効です。
検索と生成が早いツールを選択する
生成時間は、コンピュータの能力やソフトウェアの処理時間にも左右されます。処理能力が高いコンピュータ(サーバー)を用意し、検索能力と生成能力が高いソフトウェアを使用することも応答時間短縮の有効策となります。
運用に関わる準備
運用に関わる準備として、以下のようなことを定期的に行える運用体制を整えておきます。
データを最新に保つ工夫
先述のように古いデータは誤回答の元になります。常に最新のデータを外部情報に格納できるようにデータ管理を徹底しましょう。
データを常に構造化する
データが検索されやすくするために、また応答時間を短くするためにも常にデータは構造化しておきましょう。
新しいデータの定期的なチャンキング
新しく追加するデータは必ずチャンキングを行い、最適な長さのチャンクに加工しておきましょう。
不要なデータの逐次削除
不要なデータの存在は、応答までの時間を長くしてしまいます。明らかに不要なデータは逐次削除をしておきましょう。
導入に関わるコストの算出
最後は、生成AIやRAG導入に関わるコストについてです。コストは導入コストと運用コストに分かれます。

導入コスト
生成AIやRAGの導入に関わる初期費用を算出します。生成AIやRAGを提供するシステム会社によっては、月々の利用料のほかに設定のための初期費用が必要になります。特にRAGの場合は、検索用データベース構築と前処理を外注すれば、それだけ費用がかかります。また、能力の高いサーバーや外部記憶装置が必要な場合は、予算化し固定資産として計上しておく必要があるでしょう。
運用コスト
生成AIシステムの運用にどれだけのコストがかかるのかを算出します。システム会社に支払う利用料のほかに、データの整理やメンテナンスにかかる人件費、長期的にはサーバーの置き換え費用なども見込んでおく必要があります。
専門のベンダーが提供しているRAG製品の導入を検討してみては
RAGは企業の業務効率化とナレッジ活用を促進しますが、ここまで書いてきたように専門的な技術が必要となり、導入には高いハードルがあります。また、導入後の運用に関わる注意点も多いため、専門ベンダーの製品を活用するのがおすすめです。
CAIWA Service ViiiのRAG機能について

イクシーズラボが提供しているAIチャットボット「CAIWA Service Viii」のRAG機能が搭載されていて、以下のような特徴をもっています。
独自開発AI✖️生成AI
イクシーズラボが提供するRAGは、独自開発AI「CAIWA」と生成AIの応答をシームレスに連携させます。誤情報を提示するリスクがないCAIWAと、広範囲な対応ができる生成AIの良い部分を組み合わせたRAGとなっています。
簡単構築・運用
RAG機能を利用するのに必要な作業は、ドキュメントファイルをアップロードするのみです。アップロードするファイルは、PDF、PowerPoint、Word、Excel、txt、CSVに対応しています。またSharePointとも連携でき、この場合ほとんど構築や運用の手間はかかりません。
質の高い回答を提供するための工夫
精度や質の高い回答を提供するために、以下のような機能を実装しています。
・ベクトル検索機能
・精度の高いチャンク抽出機能
・テストを重ね最適化されたプロンプト提供
・生成元ファイルの表示機能。ファクトチェックが可能
QA自動生成
イクシーズラボのRAGは、ドキュメントからQAを生成する機能があり、独自開発AI「CAIWA」のナレッジとして簡単に追加できます。QAはクリック1回で自動生成することが可能です。CAIWAは言葉の曖昧さに対応しながら、登録されたQAの範囲内で回答を提示します。そのため、登録されていない質問に答えることはできませんが、回答内容の精査・編集が可能なため、誤情報が含まれるリスクがありません。
コストについて
QA自動生成機能はCAIWA Service Viiiの標準機能で、応答機能はオプションとなりますが一律で低価格となっています。詳しくは弊社の営業担当に直接お尋ねください。
言語認識精度が高くメンテナンスも楽なCAIWA Service Viii
株式会社イクシーズラボが提供するCAIWA Service Viiiには、以下のような特徴があります。
高い言語認識精度
言語認識精度が高い自社開発のAI会話エンジン「CAIWA」によって初期状態でも高い正答率を実現しています。
簡単構築、らくらく運用
直感的に扱える管理ツール「CAIWA ROBOT MANAGER」と、ChatGPT API連携機能で構築・運用の手間を解消しています。
各種連携機能
ChatGPT APIやMicrosoft Teams、LINEとの連携、翻訳システムとの連携による多言語対応など、外部システムやアプリケーションと連携することで幅広い顧客ニーズに対応します。
まとめ
RAGはハルシネーション防止のために非常に有効な機能ですが、導入やその後の運用には高いハードルがあります。株式会社イクシーズラボが提供するCAIWA Service Viiiに備わるRAGであれば、そうしたハードルに悩まされることなく、リーズナブルな価格で高い効果を実感できるでしょう。

